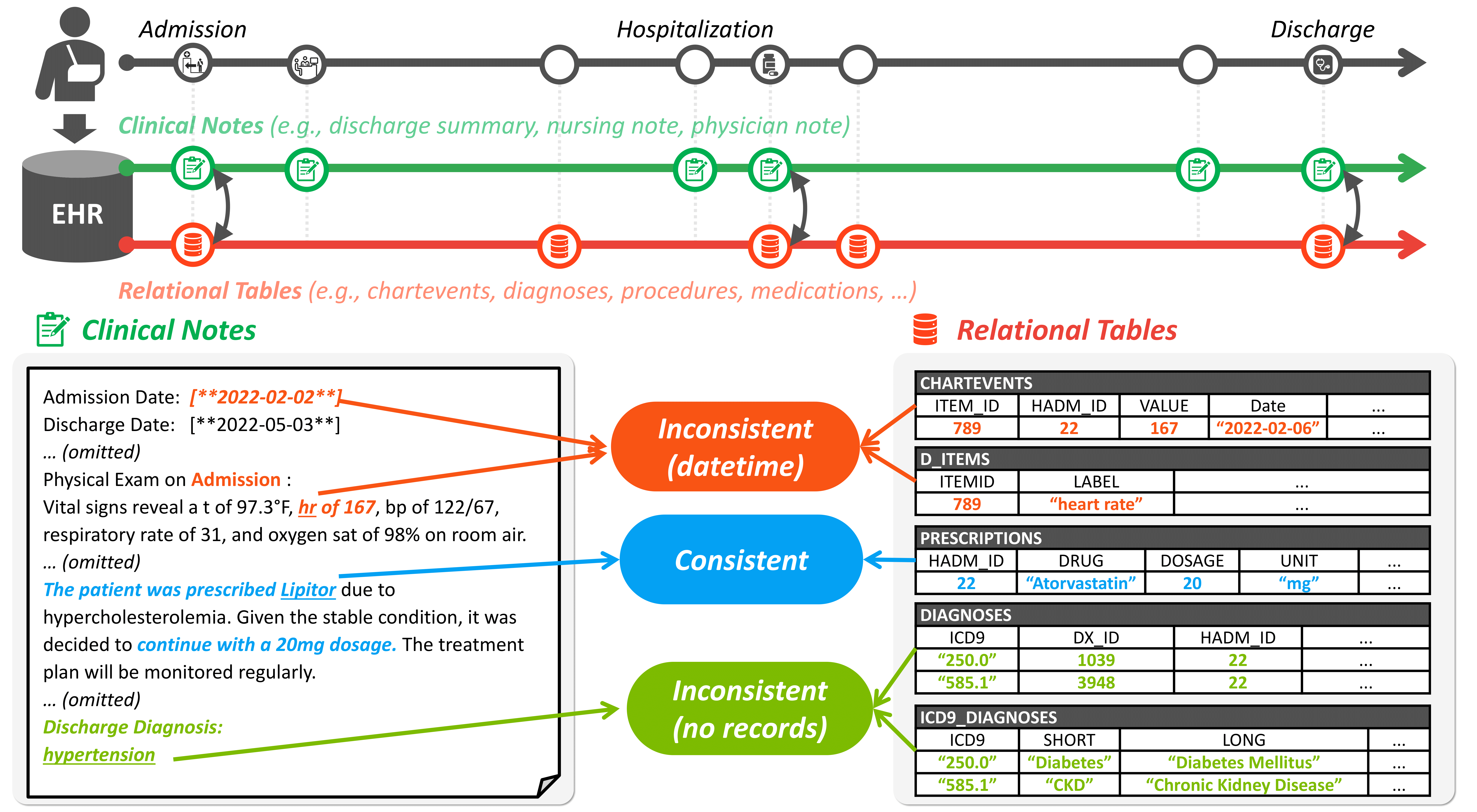
Electronic Health Records (EHRs) are integral for storing comprehensive patient medical records, combining structured data (e.g., medications) with detailed clinical notes (e.g., physician notes). These elements are essential for straightforward data retrieval and provide deep, contextual insights into patient care. However, they often suffer from discrepancies due to unintuitive EHR system designs and human errors, posing serious risks to patient safety. To address this, we developed EHRCon, a new dataset and task specifically designed to ensure data consistency between structured tables and unstructured notes in EHRs. EHRCon was crafted in collaboration with healthcare professionals using the MIMIC-III EHR dataset, and includes manual annotations of 4,101 entities across 105 clinical notes checked against database entries for consistency. EHRCon has two versions, one using the original MIMIC- III schema, and another using the OMOP CDM schema, in order to increase its applicability and generalizability. Furthermore, leveraging the capabilities of large language models, we introduce CheckEHR, a novel framework for verifying the consistency between clinical notes and database tables. CheckEHR utilizes an eight-stage process and shows promising results in both few-shot and zero-shot settings.
EHRCon includes annotations for 4,101 entities extracted from 105 randomly selected clinical notes, evaluated against 13 tables within the MIMIC-III database. MIMIC-III contains data from approximately 40,000 ICU patients treated at Beth Israel Deaconess Medical Center between 2001 and 2012, encompassing both structured information and textual records. To enhance standardization, we also utilize the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) version of MIMIC-III. OMOP CDM, a publicly developed data standard designed to unify the format and content of observational data for efficient and reliable biomedical research.
EHRs consist of comprehensive digital data, including structured data (like medications and diagnoses) and clinical notes, which offer detailed patient insights. These elements are interconnected and crucial for diagnosis and treatment, with structured data allowing for easy data retrieval and clinical notes providing deeper context. However, inconsistencies often occur between these data forms due to issues like EHR interface design, which is more focused on administrative tasks, and errors made by overburdened practitioners. These discrepancies can endanger patient safety and lead to legal problems. Current methods for checking data consistency between tables and text are inadequate, as they typically handle simpler cases and are not scalable for complex EHR systems. To address this, a new task and dataset named EHRCon is proposed to verify consistency between clinical notes and large relational databases within EHRs, emphasizing the need for more robust, automated solutions.
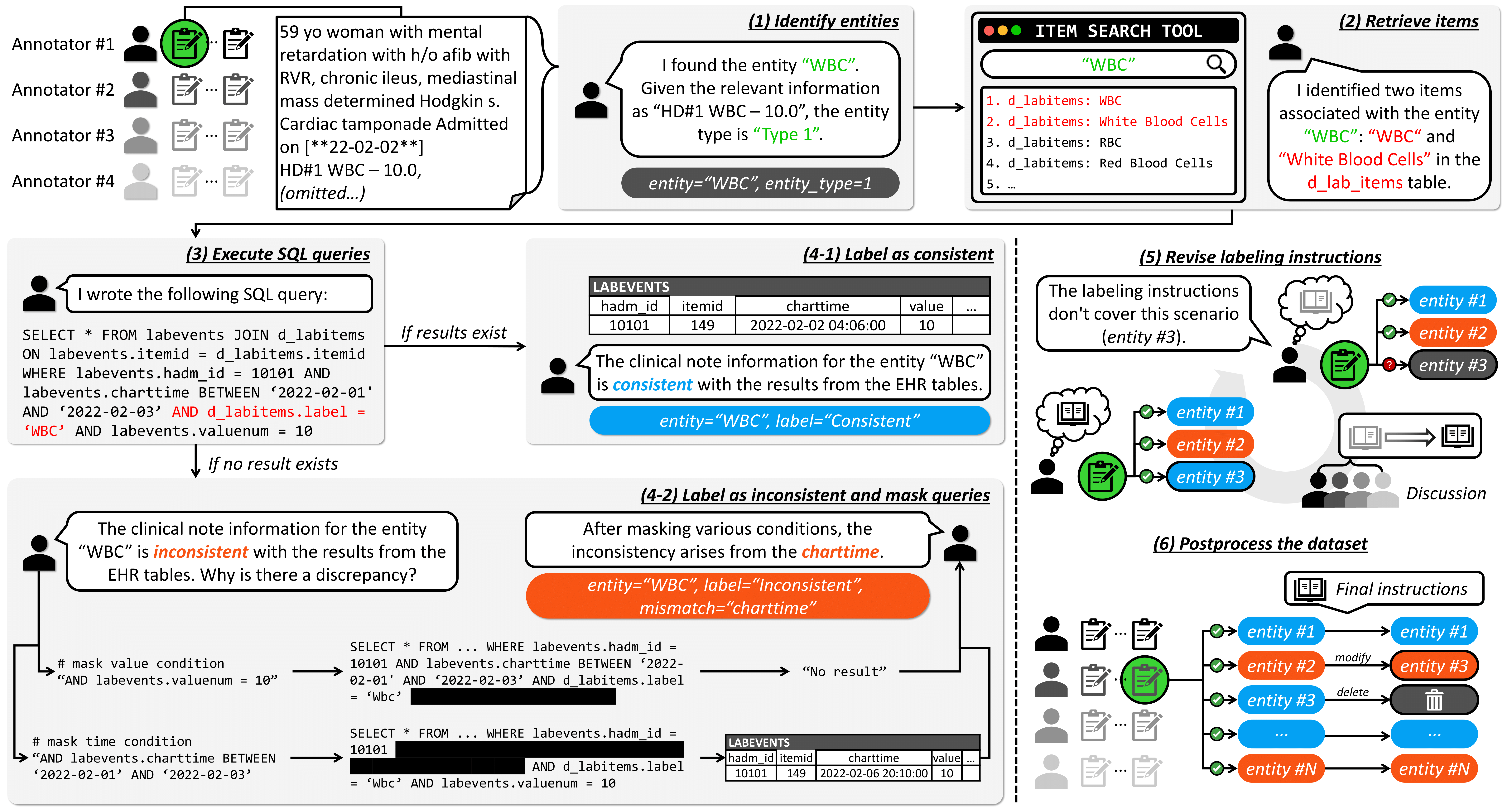
To reflect actual hospital environments, practitioners and AI researchers collaboratively designed the labeling instructions. Using these labeling instructions, the dataset was created through the following process.
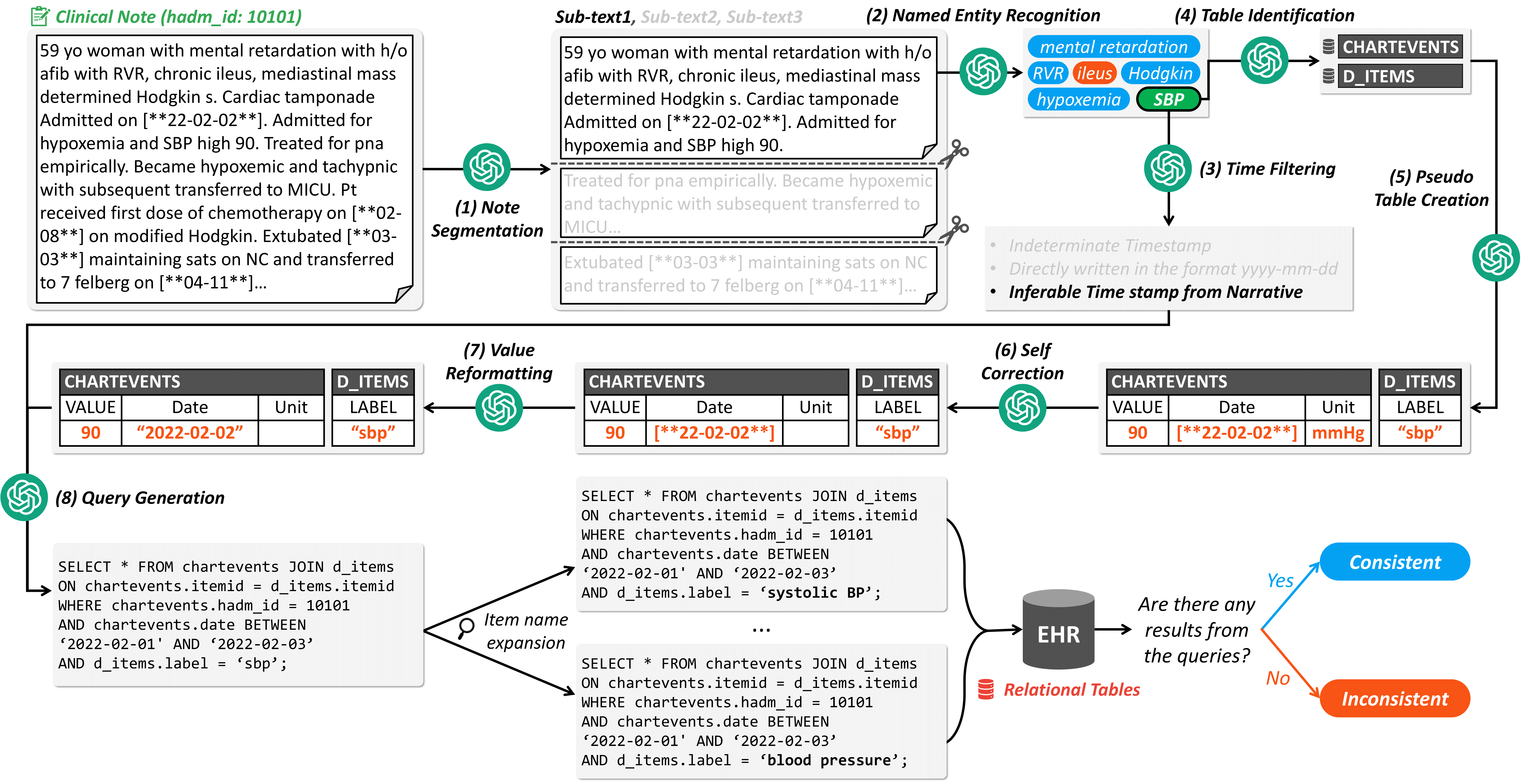
CheckEHR is a novel framework designed to automatically verify the consistency between clinical notes and a relational database. CheckEHR encompasses eight sequential stages: Note Segmentation, Named Entity Recognition (NER), Time Filtering, Table Identification, Pseudo Table Creation, Self Correction, Value Reformatting, and Query Generation. All stages utilize the in-context learning method with a few examples to maximize the reasoning ability of large language models (LLMs).
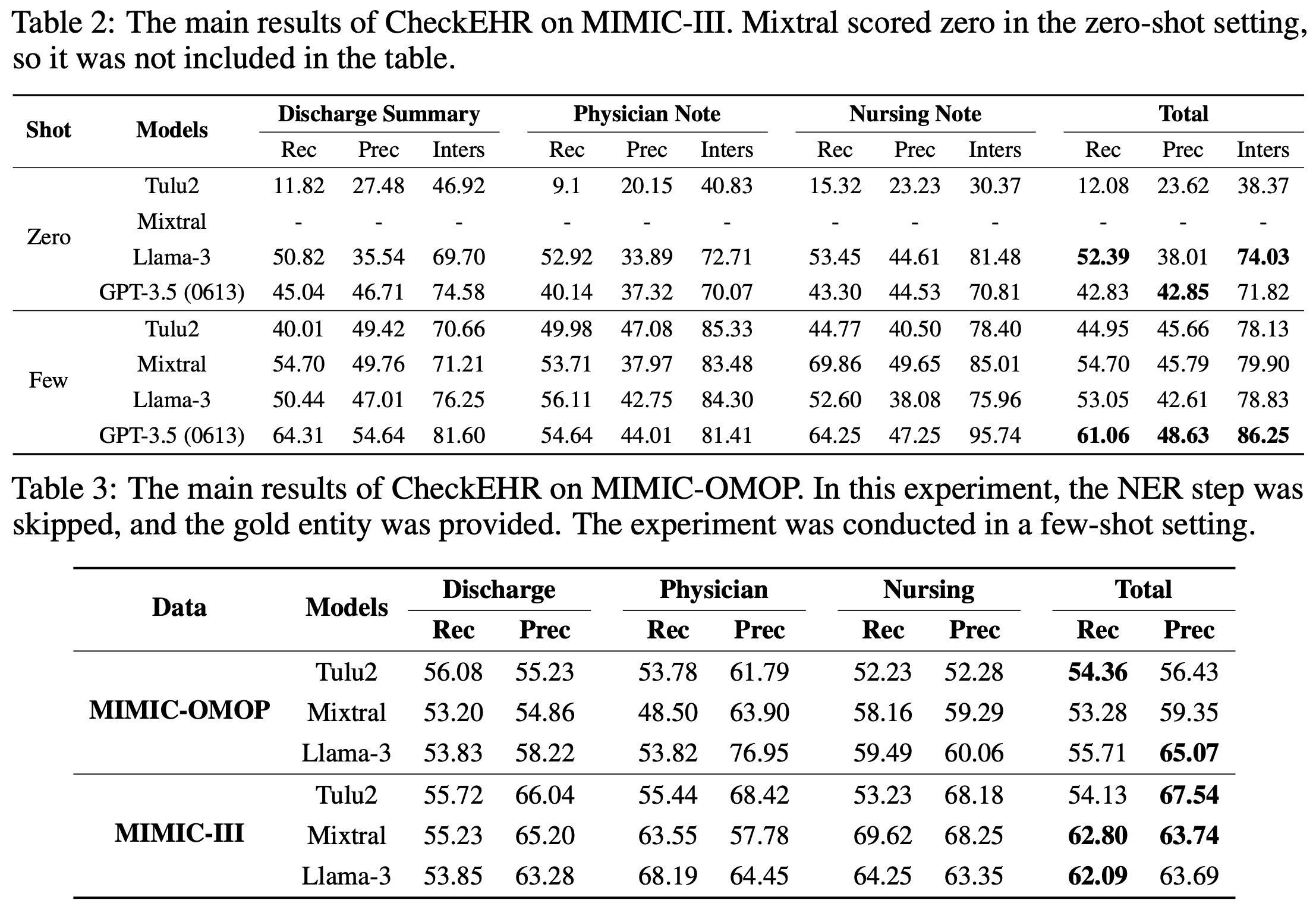
1. The challenging nature of the task: Table 2 indicates that using GPT-3.5 (0613) in a few-shot setting yields the highest scores. However, recall scores for baseline models fluctuate between 40-60%, demonstrating the task's complexity. This challenge is further underscored by the significant gaps between recall and intersection, and between precision and intersection. Such discrepancies indicate the difficulty of NER in our task.
2. Few-shot Vs. Zero-shot: Models such as Tulu2, Mixtral, and GPT-3.5 (0613) demonstrate significant improvements in few-shot scenarios, while Llama-3's performance remains consistent across zero-shot and few-shot settings. Notably, few-shot learning enhances Llama-3's capabilities in discharge summaries and physician notes but diminishes its effectiveness in nursing notes. This variation suggests that Llama-3 struggles with generalizing from in-context examples, especially in the more unstructured formats of nursing notes.
3. MIMIC-III Vs. MIMIC-OMOP: The MIMIC-III and OMOP CDM databases organize the same clinical event data in different formats, with MIMIC-III utilizing multiple specific tables and OMOP CDM employing standardized tables for easier identification and search. Despite the simplified structure of OMOP CDM, which was expected to enhance performance, the actual performance of the MIMIC-OMOP integration was similar to or worse than MIMIC-III. This was attributed to the complexity of the entities within the MIMIC-OMOP database, which includes detailed and diverse information related to specific entity names, such as "Cipralex 10mg tablets (Sigma Pharmaceuticals Plc) 28 tablets", encompassing value, unit, and other related details all at once. Our findings underscore the necessity for developing a framework that can interact flexibly with the database to overcome these challenges in future research.
@article{kwon2024ehrcon,
author = {Kwon, Yeonsu and Kim, Jiho and Lee, Gyubok and Bae, Seongsu and Kyung, Daeun and Cha, Wonchul and Pollard, Tom and Johnson, Alistair and Choi, Edward},
title = {EHRCon: Dataset for Checking Consistency between Unstructured Notes and Structured Tables in Electronic Health Records},
journal = {arXiv preprint arXiv:2406.16341},
year = {2024},
}